Tag: data
-
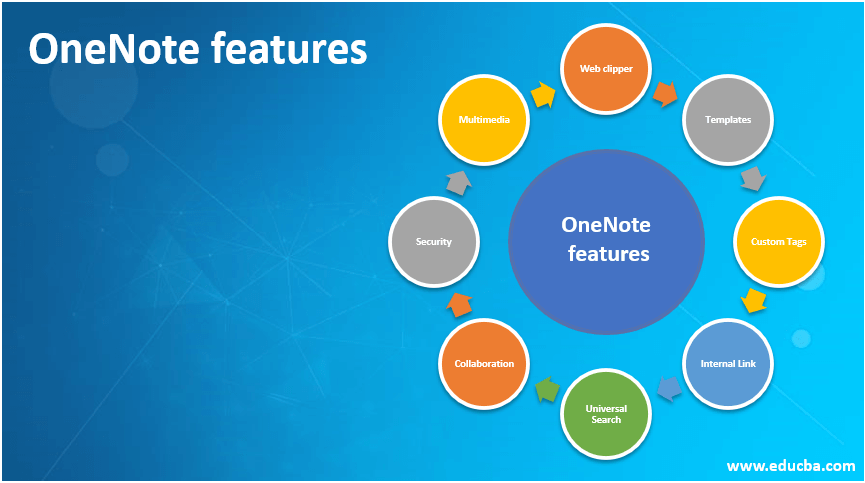
OneNote features
Introduction to OneNote features OneNote features empower users to capture their ideas, views, notes, personal contents, blogs, general information, contact details, drawings, weblinks, scans, to-do lists through multiple devices like mobiles, laptops, tabs that use several operating systems like Android, Windows, MAC from any location on the go and store the captured information in an…
-

All of the best Tello mobile cell phone plans available now
Tello is a unique carrier in that it doesn’t have a traditional set of plans, instead, the best Tello plans can be customized for each person. This includes choosing how many minutes and minutes they want, plus data. Tello operates on the T-Mobile network with access to 5G including the faster mid-band connection. While you…
-

How to avoid data breaches and keep your personal data secure online
Data breaches are a danger for anybody who utilizes the web, no matter their age. Anchiy/Getty Images .An information breach is when your individual information is accessed, copied, or altered by somebody without your approval.The majority of information breaches include hacked e-mail accounts and taken bank details.The very best method to safeguard versus information breaches…